So you signed up for your first hackathon…
About a year ago I was (luckily) invited to attend Neurohackademy at the University of Washington, Seattle. This was my first time even hearing about hackathons in neuroimaging, so I was definitely excited to check it out. The format of the 2-week event was perfect for me: one week of broad introductions to tools and perspectives that we were encouraged to implement during the second week in collectively-idealized projects. While excited, the part of me perennially afflicted by the impostor syndrome never stopped asking “what could I possibly contribute to projects that other people can’t already do?” Turns out not that much. But I also learned that hackathons are as much about learning as they are about contributing, and even small contributions are welcomed. So I’m writing this short post for those who, like me, might be nervous about the prospect of their first hackathon.
Let’s get something out of the way: the core idea of a hackathon is appealing to people who are heavily invested in open, community driven scientific projects and tools. This, in my opinion, has two comforting consequences: (1) those around you will (most likely) be more into collaboration than competition; and (2) anyone who has worked in open science knows that projects seldom reach perfection (just go and look at the ‘Issues’ section of any open repo you admire). This coarsely translates into: you don’t have to prove yourself to anyone, and it’s ok if the projects you dig into are not at their ideal stage by the end of the hackathon. Hopefully that takes some pressure off your shoulders.
You might still be wondering whether your level of skill will match the requirements of the project(s) you affiliate with. After all, many of those around you will have extensive knowledge of things like git, open-source programing languages, continuous integration, notebook implementation (e.g. Jupyter), package development, environment sharing tools, community guidelines, etc. Knowing that the collective knowledge of a room is miles ahead of mine has always been a reliable depressor for me (this makes living in Boston challenging at times). What if these experienced people expect basic expertise? Well, let me tell you about some of the things I (and other newbies) did for the first time during Neurohackademy:
I issued my first pull request. I literally just added a file to NiBetaSeries, with James Kent patiently guiding me through the process. Before then I had just used GitHub to keep track of my own projects.
Python dominated the hackathon. I did not dominate Python. I was just getting used to R at that time, and I didn’t even know what a ‘class’ object was. Heck, I had never even loaded a custom package locally before someone at NH showed me how to.
Opened and edited a Jupyter notebook.
My main group almost broke a repository, and Kirstie Whitaker spent a charitable couple of hours helping us fix it.
Looked at C++ code (yes, looked. I didn’t even try to touch it).
Etc. A lot of etc.
Many of these are what many would consider “basic knowledge”, yet plenty of such first encounters occurred. What’s more, it’s possible that some of these first encounters will be about things you do know about, and will be able to help others with! As a personal example, someone in a different group had a question about R that I helped tackle to some degree. Super simple, I know, but hackathons are all about helping each other in both big and small ways. Every bit counts when a bunch of people stuck in a room are trying to push science forward. I guess what I’m trying to convery here is: as long as you come in with the right collaborating (and respectful) attitude, both you and others will get something out of this experience.
Ok ok, but what did you actually work on?
Maybe describing my experience will make all of this more tangible.
The main project I plugged myself into was already kind of in the oven before NH. Michael Notter had been working on a Python tool to parcellate a cortical surface (or a region within it) into n equally-sized regions. He called it the “parcellation fragmenter”. I liked this project because I had recently been learning about clustering algorithms for my own work, and there were talks about implementing one of my favorite ones into the clustering catalogue (spectral partitioning). Here’s an example of what this looks like for different surface shapes and densities:
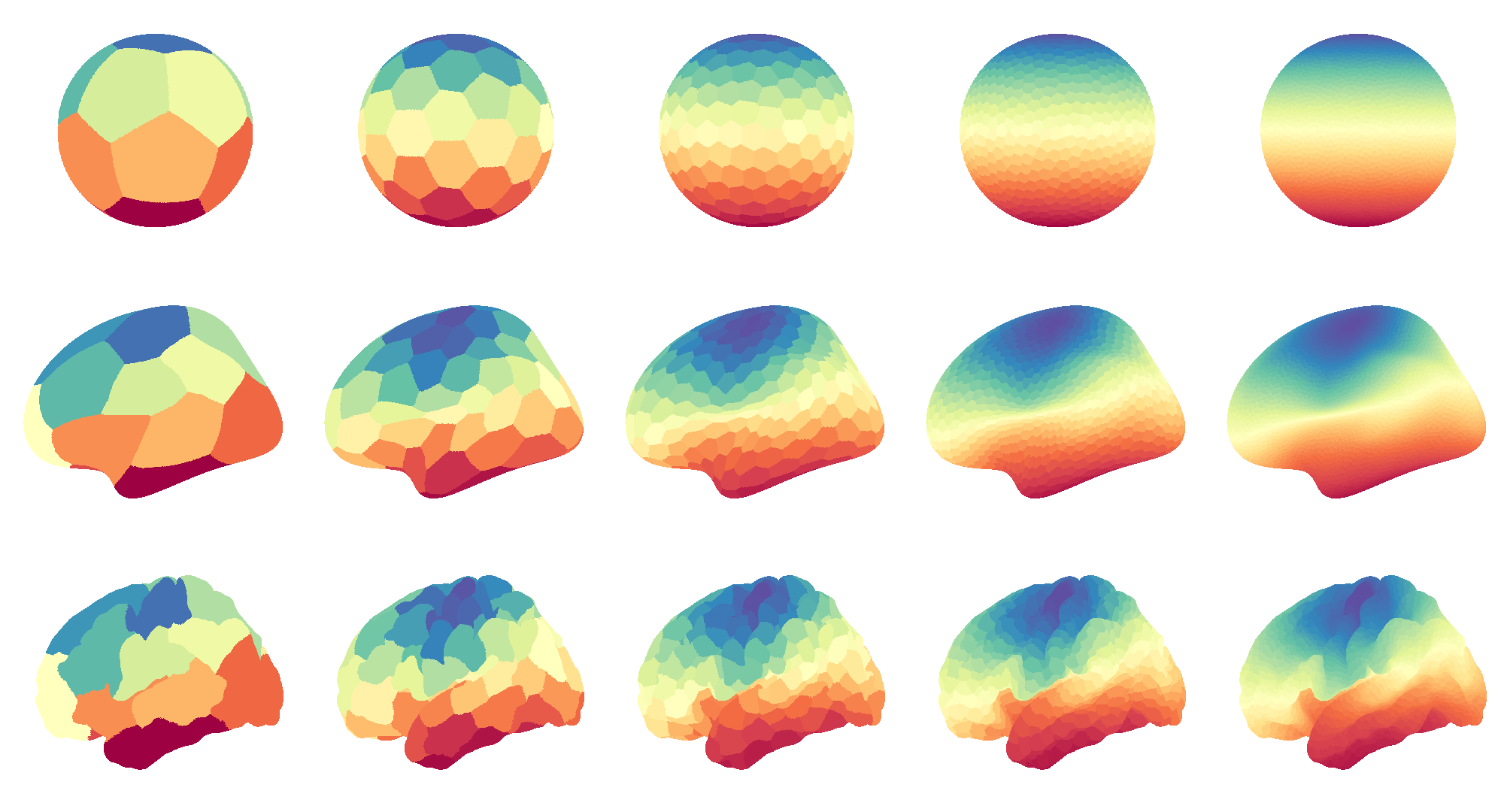 Not only did I love the look of those fragmented brains, I also thought I could help with the addition of spectral partitioning. Well, that wasn’t the case. Kristian Eschenburg had it under control from the get-go, and he implemented much of the code and technical reframing of the package. Luckily for me, both him and Michael were happy to guide me through tractable issues and testing that I could do, which helped me learn Python better. Even though the work seemed inconsequential, it did benefit the project to some extent: I found a pair of hiccups in the calculation of distances between cortical vertices (super important for any clustering algorithm), among other tiny fixes.
Not only did I love the look of those fragmented brains, I also thought I could help with the addition of spectral partitioning. Well, that wasn’t the case. Kristian Eschenburg had it under control from the get-go, and he implemented much of the code and technical reframing of the package. Luckily for me, both him and Michael were happy to guide me through tractable issues and testing that I could do, which helped me learn Python better. Even though the work seemed inconsequential, it did benefit the project to some extent: I found a pair of hiccups in the calculation of distances between cortical vertices (super important for any clustering algorithm), among other tiny fixes.
Even though I felt welcomed to the project and I loved learning, I also felt bad for not being able to contribute more substantially. At this point something clicked: I was trying to add content where someone else’s expertise worked better, but I wasn’t trying to help the project in new ways that I knew I was capable of. That’s when I proposed something very simple to Michael and Kristian: what if we benchmark the algorithms you are implementing here? The idea was to add information on reliability and efficiency of the algorithms to help future users decide which clustering method to use. Fortunately they liked the idea, and all I had to do was produce the following three figures (and a short Jupyter notebook to display them along with their code):
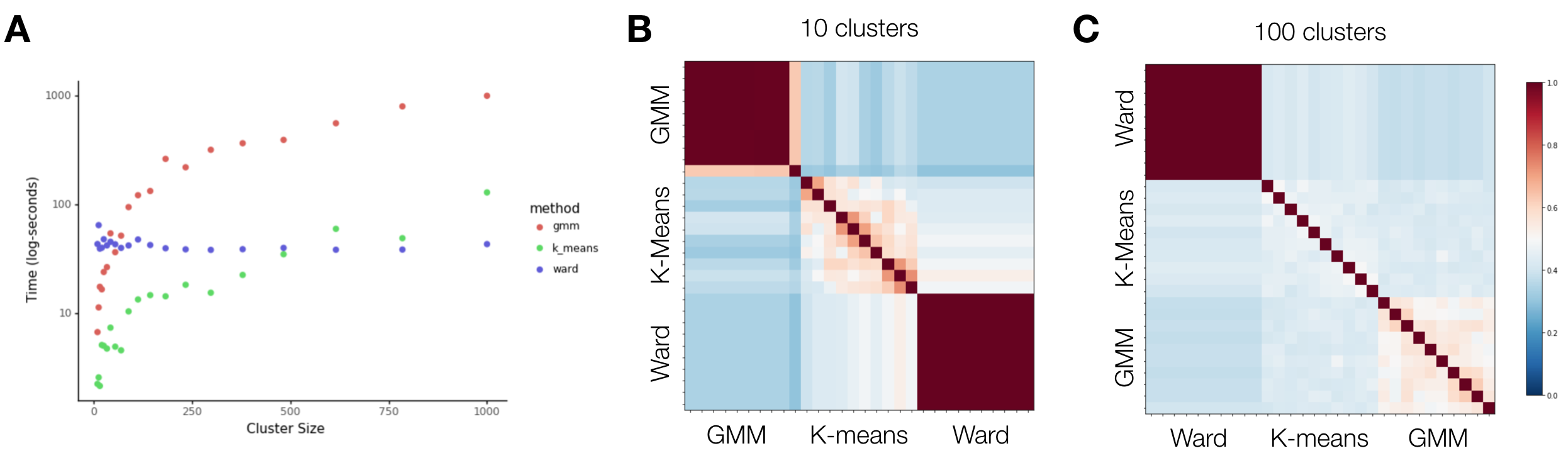
Just so you’re not left hanging, this is what they mean: A shows how long it takes each algorithm to produce brain parcellations as a function of the desired number of clusters. B and C, on the other hand, tell you how similar partitions are if you re-run the code 10 times for parcellations of 10 and 100 clusters (i.e. how reliable each method is). The similarities were computed using the adjusted Rand Index, which I’ve covered in an older post. Perhaps unsurprisingly, this shows that k-means is fast, but also highly variable (which can be helpful if you want many slight variations for a permutation, for example), whereas Ward is both relatively fast and highly stable across iterations. Spectral partitioning is not shown because it’s extra slow, but also extra stable.
So, what are the takeaways here? First, you can tell that a week of experience didn’t prevent me from making silly mistakes in Python, as I couldn’t quite get the order of the algorithms to match across the similarity matrices above. And second, that even something as straightforward as this can be a valued addition to a project, even if it doesn’t directly affect the way the package/tool/project works. As long as it’s relevant to the project and/or it helps you grow, then there is value in pursuing it (or at least proposing it).
Just a tad more
So yes, hackathons are more than just rushing to complete a project, as I thought they would be before I attended Neurohackademy. Sure, many great projects will be pretty polished (here’s an example), but likely not all will. They’re a great place to learn and gain confidence to continue helping the open community at large. You’ll probably learn tools like git that will be great to implement in your own work. Beyond that, you’ll get to meet a diverse group of people that might become collaborators in the future, or that you’ll look forward to seeing at future conferences (or at least you’ll get new twitter friends). Keep in mind that this post is based on my one experience (plus other people’s anecdotes), but if you’re concerned about fitting in at your first hackathon (like I was), hopefully this short post can help you get rid of those thoughts.